I Built a RAG System in 2018 (I Just Didn’t Know It Yet)
I rebuilt my 2018 movie recommendation engine using the 2026 Stack (Vertex AI, pgvector, Gemini, Chainlit). A deep dive into moving from pixel-matching to semantic RAG, Unit Economics, and AI Compliance.

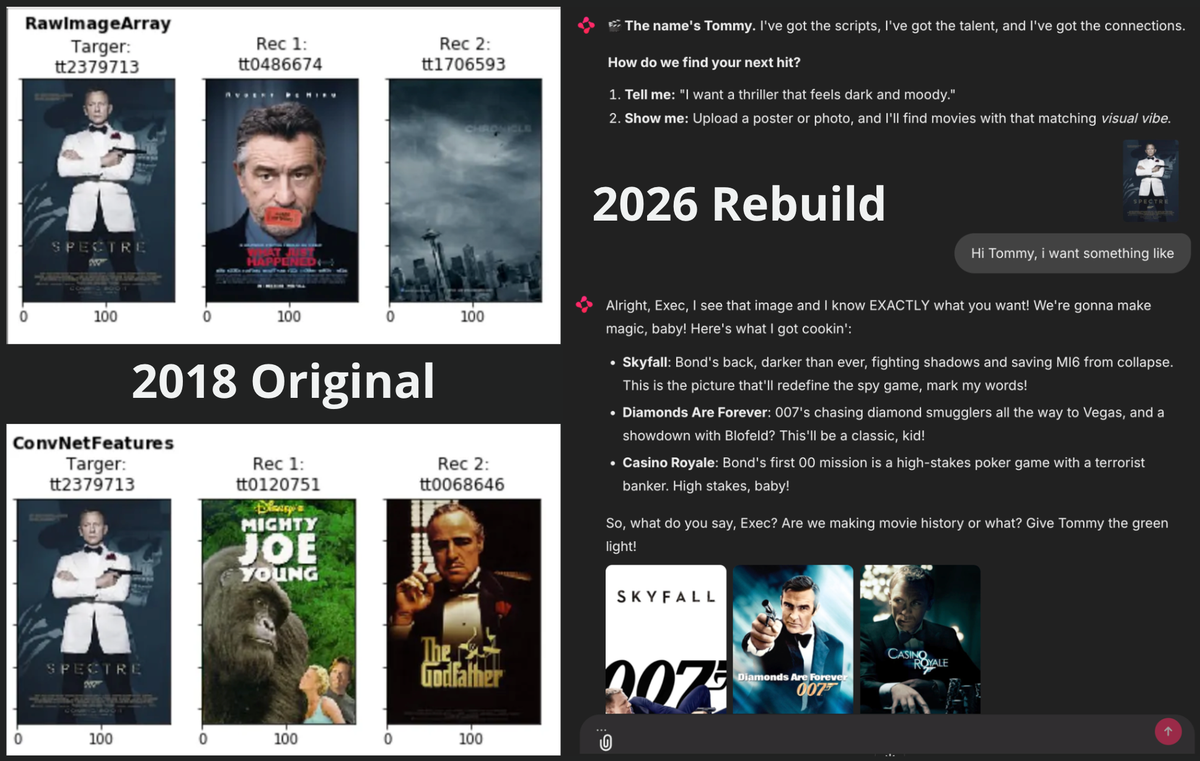
In 2018, I was curious if a machine could "see" movie genres. I wrote an article about using Inception-v3, the state-of-the-art computer vision model at the time, to recommend movie posters based on visual similarity. The idea was simple: if a computer looks at a James Bond poster, can it intuitively find other movies that look like it?
Back then, I called this "Feature Extraction" and "Nearest Neighbors". Today, the industry calls it Vector Embeddings and RAG (Retreval-Augmented Generation).
I decided to rebuild that old project using the modern 2026 AI stack (Vertex AI, pgvector, Gemini, and Chainlit). I wanted to see exactly what has changed in the last eight years and what hasn’t.
Looking at the code side-by-side, the fundamental engineering logic is identical. We are still mapping unstructured data to vector space and optimizing retrieval. But while the logic is the same, the semantic understanding and production reality has evolved drastically. Before we break down the technical stack, here is the 2026 rebuild in action.
1. The Logic: Pattern Matching vs. Understanding
The core of any recommendation system is understanding what an item is. This is where the leap from 2018 to today is most visible.
2018 The "Pixel" Approach: In my original project, I used a standard Convolutional Neural Network (CNN). The model didn't know what a "movie" was. It only knew shapes, edges, and colors. If the Spectre poster had dark blue hues and a gun silhouette, the model optimized to find other posters with dark blue hues and gun silhouettes.
It worked, but it had a blind spot. It matched patterns, not concepts. If a Horror movie had the same lighting layout as James Bond, my 2018 model would recommend it.
2026 The Semantic Approach: For the rebuild, I switched to Vertex AI's Multimodal Embedding model from the Google Cloud Model Garden to map images and text into a shared vector space. Moving beyond 'reading' or 'seeing,' the model uses learned high-dimensional patterns to identify that a picture of a tuxedo and the word 'suave' occupy the same semantic neighborhood.
Now, instead of just matching colors, I can search for concepts like "A spy movie with a dark, minimalist atmosphere." The system retrieves Spectre not just because of its pixels, but because the vector representation aligns with the concept of a "dark spy atmosphere."
2. Getting the Data: From Fragile Scripts to APIs
One of the biggest differences between my 2018 self and my 2026 self isn't just the AI models. It is how I view data engineering.
2018 Scraping: Back then, I just wanted the data fast. I wrote Python scripts using BeautifulSoup to parse HTML <div> tags. It was messy. If the website changed a CSS class, my pipeline broke. I probably spent more time fixing the scraper than building the actual model.
2026 Reliability: For the modern architecture, I prioritized stability. Instead of scraping, I used the TMDB (The Movie Database) API. It provides structured JSON and consistent metadata.
It is a simple lesson, but a critical one for production systems. Relying on HTML scraping is technical debt. Using an API ensures that the "Raw Data" is reliable before it ever touches the AI.
3. Architecture: Moving Vectors into the Database
2018 RAM Dependency: In the first version, I held a sklearn Ball Tree index entirely in RAM. It was fast enough for 5,000 movies, but fragile. If the server restarted, the index died.
2026 Convergence with pgvector: For this rebuild, I consolidated everything into PostgreSQL using the pgvector extension.
This simplifies the stack immensely. I can store the 1408-dimensional Vertex AI embeddings in the same row as the movie title. Using HNSW (Hierarchical Navigable Small World) indexing inside Postgres allows for millisecond retrieval. A single SQL query now handles both the semantic search and the metadata retrieval, with zero network overhead between a "Vector DB" and a "SQL DB." It is simply more pragmatic. Don't take my word for it. Spin up a Postgres instance and see the complexity drop for yourself.
4. The "G" in RAG: Steering via Context, Not Training
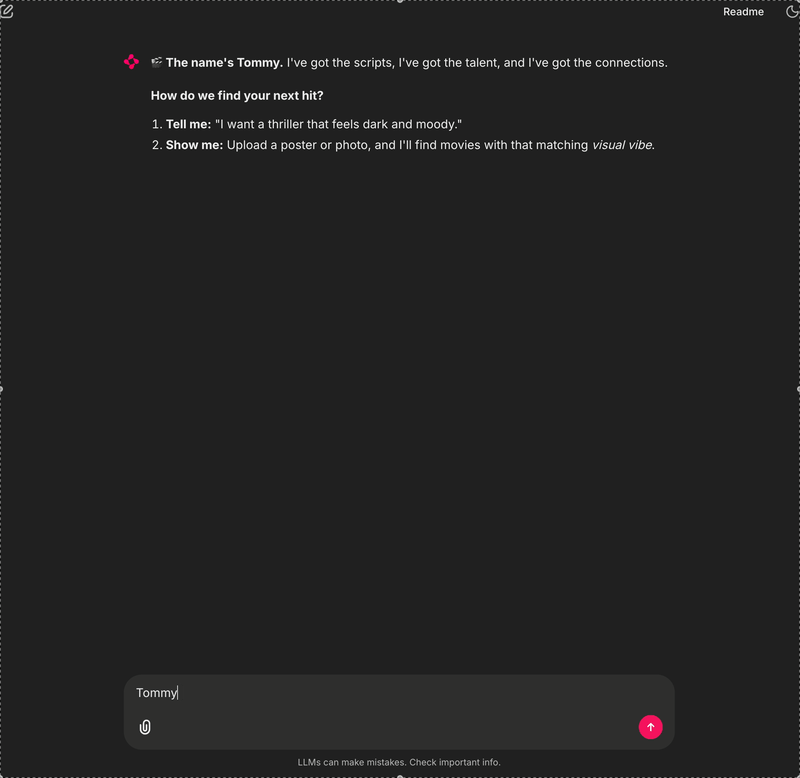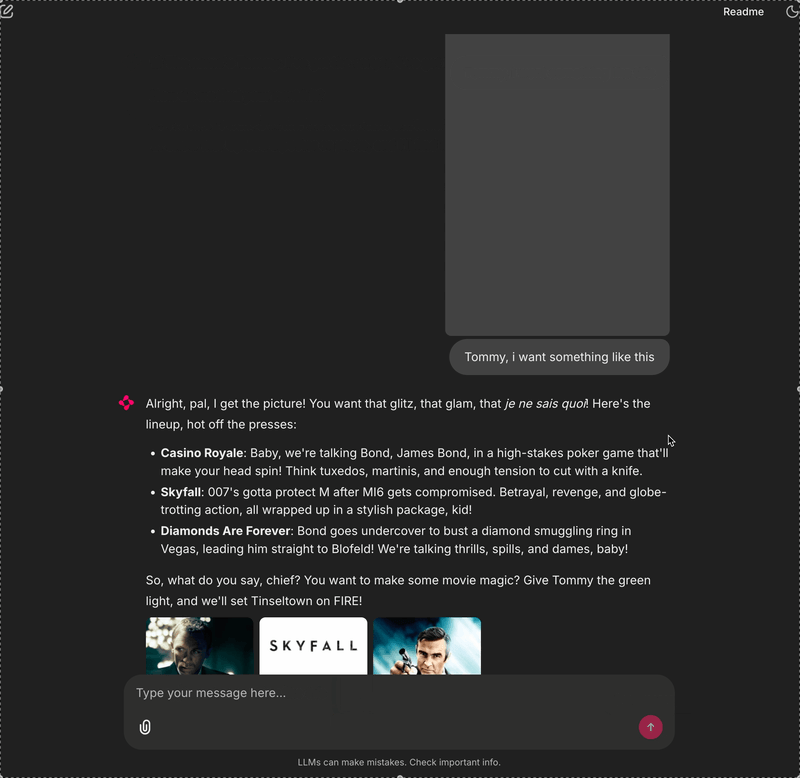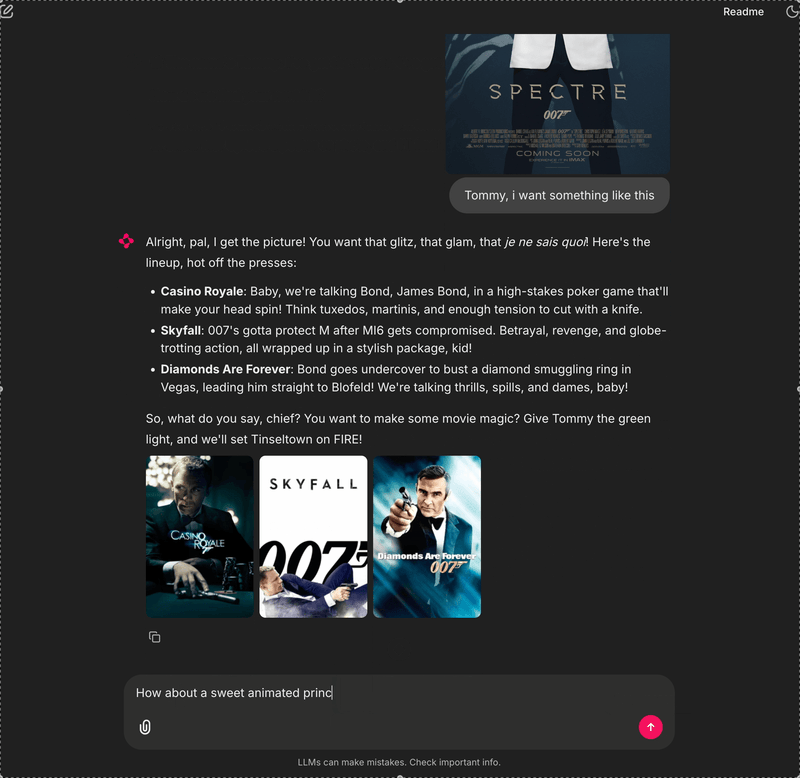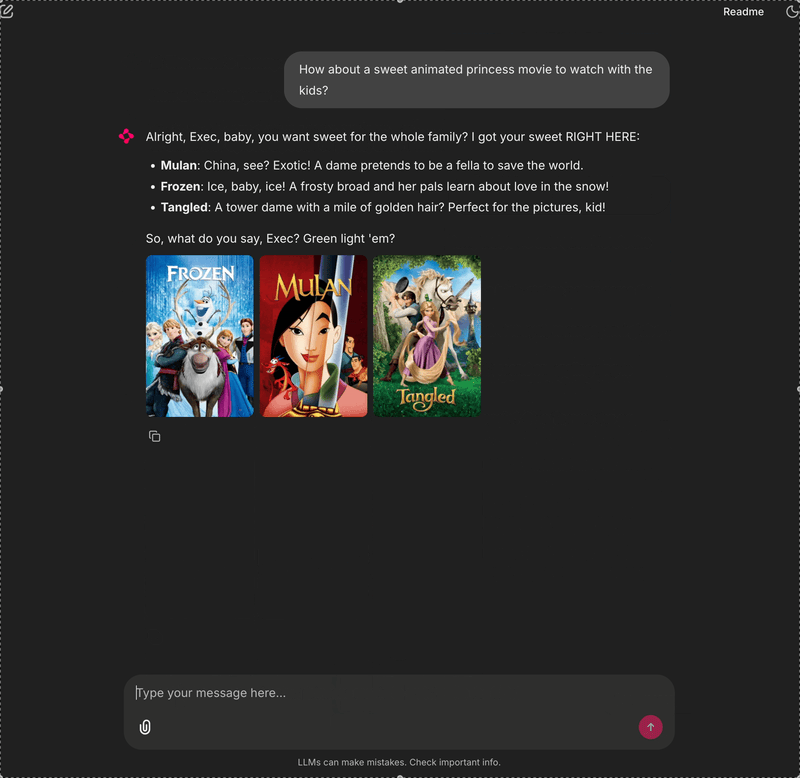
This is the piece that didn't exist in 2018. My old app just showed you pictures (Retrieval). To make it a RAG system, I added the Generation layer using Gemini 2.0 Flash.
However, a raw LLM (Large Language Models) response can be dry. I wanted a specific user experience, a fast-talking 1960s Hollywood Agent named "Tommy."
The Engineering Choice. Prompting vs. Fine-Tuning: In enterprise AI, we often debate the best way to steer a model. You can fine-tune a model on a curated dataset, but that introduces significant "maintenance debt." Every time the business requirements change, you have to re-train and re-deploy. This includes the tone, the output format, or the reasoning logic. That burns budget and slows down iteration.
I chose System Instruction Prompting for one reason: Velocity.
I treat the LLM as a general-purpose reasoning engine. By injecting strict system instructions alongside the user's query, I can steer the behavior instantly. If I need to switch from a conversational summary to a strict JSON output, I just change one line of code. No GPU training required.
System Instruction: "You are Tommy, a high-energy 1960s Talent Agent. Use slang like 'kid' and 'box office gold'. Sell the movie, don't just summarize it."
I gave Tommy multimodal capabilities, meaning he can handle both text and image inputs provided by the user. It effectively becomes a "Tell me or Show me" interface:
- User: "I want a gritty sci-fi movie." or [Upload a poster]
- Tommy's Response: "Baby, you want dark and gritty? I got just the thing! Look at District 9..."
The Safety Layer: It is not all fun and games. Production AI requires active defense. In my professional work, I dedicate significant time to Legal and Cybersecurity alignment, specifically navigating GDPR and the EU AI Act. I focus on data, hosting and enabling strict guardrails like Vertex AI Safety Attributes to ensure our systems are not just powerful, but compliant. For instance, before "Tommy" even processes your photo or reads your text, the system runs a content classification check for Hate Speech, Harassment, and Sexually Explicit content.That invisible layer is the difference between a fun demo I use in this blog and a system that is production-ready.
Business Value & The Hidden Context Cost: I use this RAG approach frequently in enterprise work because it allows us to validate product value in days, not months. We don't need a team of ML engineers to fine-tune a model for every new feature. We just need effective context engineering to turn a generic model into a specialized tool.
This is the value side, but what about the cost side? You need to manage both for high-ROI projects. Unit Economics is key, how financial efficiency is the product. Scaling an expensive solution is perhaps not in the best interest of your wallet. In 2026, building in the cloud means every token has a price tag. In 2018, the price structures were different, with more on-premises architecture.
For the "Tommy" interaction shown in the GIF above (with the Hi Tommy + Spectre image), the total cost is €0.00016. LLM costs are standardly quoted per 1 million tokens. The calculation goes like this: Total Cost = ((Input Tokens / 1,000,000) * Input Price) + ((Output Tokens / 1,000,000) * Output Price)
Let's look at the breakdown:
- User Query: 9 tokens (The "Ask")
- System Instructions: 535 tokens (The Persona)
- Image Overhead: 258 tokens (Spectre Image Vision)
- RAG Context: 279 tokens (The Knowledge)
- Total Input: 1,081 tokens
- Total output: 169 tokens
LLM costs are standardly quoted per 1 million tokens. In this interaction, it is also worth noting the hidden 'language tax', if this exact same user query were written in German instead of English, tokenizer inefficiencies could easily jump the user input from 9 to 14+ tokens. Subtly shifting the unit economics, a factor well worth considering when scaling your application across markets. The user input (text and image) accounted for just 25% (9+258/ 1081) of the token consumption. The remaining 75% is System Overhead, the invisible weight of the persona and retrieved context.
This shows that unit economics are largely architectural. Your margins are determined by how well you optimize what the user doesn't see.
In production RAG systems, your highest costs are not for the user's question, but for the context you feed the model. Choosing your LLM (in my case, Gemini 2.0 Flash), optimizing your chunk size, and refining your system prompts (including the language they are written in) are not just engineering decisions. They are financial ones. And they are a huge part of your project's success and ROI.
RAG vs AI Agent: You might ask: "It's 2026. Why isn't Tommy an AI Agent?" This is a deliberate choice to optimize Unit Economics and minimize Regulatory Risk.
- Economically, Agents require expensive reasoning loops for doing tasks like planning and executing tools. Every time an Agent loops, it has to re-process its massive AGENTS.md instruction file. That file is pure system overhead. It taxes your unit economics on every single step. RAG is a streamlined pipeline for knowing facts. This keeps latency low and costs predictable. Scaling an Agent loop is exponentially more expensive.
- Legally, under the 2026 EU AI Act, "Agentic" systems often fall into higher-risk categories.
By keeping Tommy as a RAG system, it is legally safer, keeps the bill lower, and ensures a short deployment timeline by bypassing heavy compliance overhead. For my goal it is simply the better risk/reward choice.
5. The Interface: Making it Usable
2018 Matplotlib: My interface was a static Matplotlib plot inside a Jupyter Notebook. It was functional code, but it wasn't a product. You couldn't "play" with it.
2026 Chainlit : I wrapped the entire pipeline in Chainlit. This provides a chat interface with native support for Multimodal Responses (Text + Images), effectively turning a data science experiment into something users can actually touch and feel.
Why this matters: Interactivity is essential to assess Product-Market Fit. By putting a UI on the model immediately, we shift from thinking about value to validating it. We can "fail fast," see how the application feels in real-time, and iterate. This ensures that we aren't just building smart algorithms, but useful tools.
6. The Anatomy of a Modern AI Product
This rebuild illustrates exactly why modern AI applications succeed. It isn't just about "using an LLM." It is about the precise combination of four distinct layers:
- Specific Knowledge (The Database): By using RAG, we ground the system in actual facts. My Postgres database holds the verified TMDB metadata. This ensures the model isn't hallucinating movie plots. It is constrained by the data I gave it.
- General Intelligence (Gemini): We rely on the pre-trained model for what it actually is, a probabilistic engine. It simply predicts the next statistically likely token based on the vast patterns it learned during training. I leverage these learned associations to handle ambiguity rather than hard-coding rules
- Steerability (The Prompt): We use the system prompt to fine-tune the delivery to our specific needs (the "Tommy" persona) without the high cost of retraining.
- User Interaction (The Feedback Loop): The UI isn't just a pretty face, it is a data collection point. In my professional work, this is where we monitor utility. The UI allows us to track how users ask questions and where the model fails.
The Result: If you remove any one of these, the system fails.
- Without RAG: It hallucinates movies that don't exist.
- Without an LLM: It’s just a keyword search engine.
- Without Prompting: It’s a dry, generic Wikipedia summarizer.
- Without UI: You are flying blind. You have no feedback loop, and no way to know if your "perfect" model is actually solving the user's problem.
Conclusion
Rebuilding this project was a reminder that while the buzzwords change, from "Feature Extraction" to "Embeddings," from "Nearest Neighbors" to "RAG", the math and goal remain the same.
It isn't about the shiny new tools. It is about the ability to take raw data and transform it into something valuable. The difference is that today, empowered by LLMs and modern infrastructure like Vertex AI, we can build in an afternoon what used to take weeks. This unlocks a level of semantic intelligence I could only dream of eight years ago.